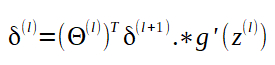I want to predict apartment prices for a given area using the size and the monthly cost, using a regression model with statistics for sold apartments in a specified area.
It is fairly simple to get a sample of past apartment deals for an area using some real estate listings.
Preparing the Data
I created a web scraper in python that is using Regular Expressions and the Requests package.
 |
| In this data set, the Price reflects the final price agreed between the seller and the buyer. |
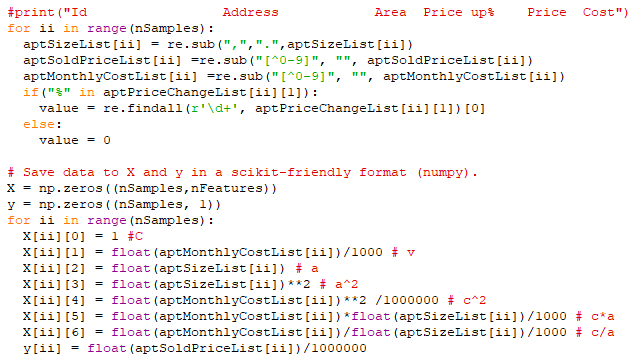
I created two numpy arrays for the raw data:
- X (number of past apartment deals, number of features)
- y (number of past apartment deals)
The Panda dataframe is populated by the two arrays:


 |
| Most of the features are derived from Cost and Area |
 |
So, just guessing that the final price would be the mean price would give an average error of 347 kSEK. This will be a measure of the model's performance: I hope that it will generate a lower error than 347 kSEK.
In the next blog post, I'll use SciKit to generate an initial prediction and evaluate that one.
Tools that I use:
SciKit is a popular package for data analysis, data mining and machine learning. I use the linear regression.
Panda is popular for machine learning too. It makes it easy to organize data
Numpy is useful for matrices, linear algebra and organizing data.
Thanks Nagesh for the inspiring article.