I have seen that I will need to check the data before adding it to the database. Sometimes, data is missing and sometimes, the data comes in a different shape.
I will discuss the issues when I see them.
Missing Price Information:
The web site that I use displays the price (the price of the last transaction) if there has been any transactions that day. If no transactions has happened that day, the price field is empty.
If that number is missing, the parameter "P" will have the value null. However, it is always possible to calculate the price by multiplying P/E by earnings per share (E). I'll illustrate with a real-world example:
On October 9th, 2014, the trade in the Swedish company Eniro was halted by the stock exchange in Stockholm and the Swedish Financial inspection. For that day, all trade was halted for Eniro and there was no price quote for that day.
| The stock price number is corresponding to Senast (Latest). Screen dump from June 2019. |
The screen shot above shows the web pages that I'm scraping. Most of the times, the fields are populated with data, but there are some exceptions. In the case of Eniro, the dividend (utdelning) and yield (direktavkastning) are omitted since there is no yield for that company. The webscraper interprets those fields to be zero.
 |
| Price is available for Eniro (10,19 SEK per share). The price corresponds to the the P/E (1,84) and Earnings per share (5,52) since 1,84 times 5.52 equals 10,16 SEK. |
- Price/Earnings rating, the Earnings per share and also
- Capital per share and the Price per capital:
 |
| On October 9th, 2014, no trades were done for Eniro. As a consequence of that, there is no record of stock price for that date. Multiplying P/E by E gives 6,77 SEK. |
I expect this to happen very seldom, but I will add a row to the database that indicates when the price information is missing. The neural network will tell whether a missing price information will predict anything in the future.
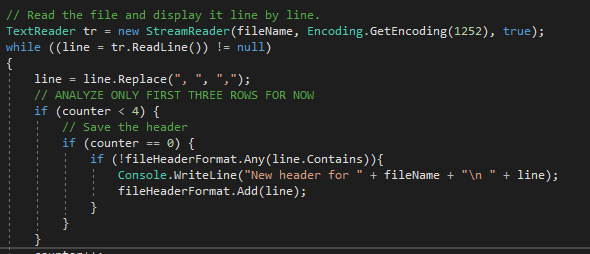
Coding:
After fetching the stock record, all data are represented O as a string list. In this case, the string for price is empty, and string2Float thus returns null.

I added a function inside the method for scanning the stock record. That function is in the same scope as the other variables and can modify them.



Now, the price is added along with an indicator of missing price. "1" indicates that the price is missing.