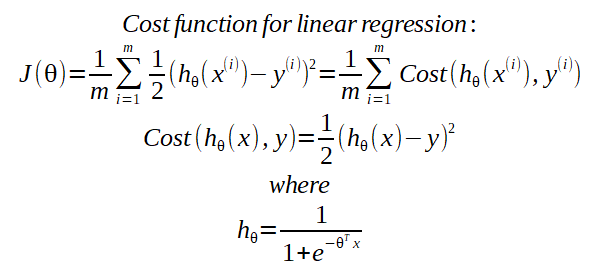Neural Networks are suitable for more non-linear representations. When the feature set gets bigger, the polynomial will be unreasonably big.
Terminology:

The course considers two types of classification: Binary and Multi-class classification.
The cost function will be a generalisation of the cost function for logistic regression. For the multi-class case, the cost function will be calculated for each output.
Back Propagation - Cost Function

The cost function for neural networks is more complex than the cost function for regularized logistic regressions, with a couple of nested summations.

- The first summation spans over the training set. This is similar to the logistic regression.
- The second summation spans over the output nodes. This means that the cost function must consider all different output bins.
- The first summation in the regularization term spans over all layers:
- The second summation in the regularization term spans over all the input nodes in the current layer, including bias unit (number of columns in the matrix)
- The third summation in the regularization terms spans over all the output nodes in the current layer, excluding the bias unit (number of rows in the matrix)