After using some neural networks to analyse a small set of data for a friends pet project, I will focus on my own data.
I have a web scraper,
StockReader, that collects some information about public stocks that are listed in Sweden. That has been in use for eight years and I have more than 1500 snapshots of a couple of hundreds of stocks.
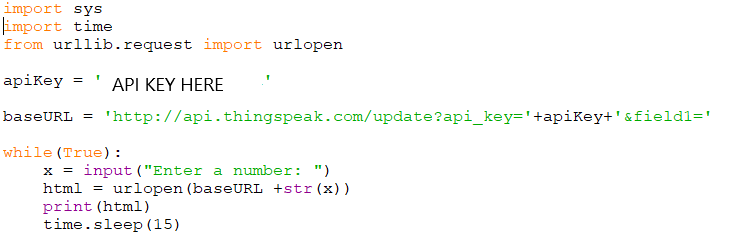
It was originally written in C++ (the code was terrible, but it was essential for me to learn to build a more complex program) and I later ported that to a twenty-four line python script that is scheduled to run three times a week.
Now, I want to use the data to learn more about machine learning and analysis of time series. I also want to get experience from C#/Visual Studio and Angular JS.
I don't expect to find a
magic algorithm that helps me in stock-picking. The purpose of this project is to learn coding, machine learning, C#, Visual Studio and Angular JS.
The Different Technology Areas for the Project
The data is saved in csv files (comma separated values). The data includes stock price, earnings per share, dividends, profit margin, RSI and date for the quarterly reports.
I will create a Windows program based on C# in Visual Studio to populate a mySQL database with the stock data. It would probably be easier using Python but I want to explore new tools and programming languages.
After the data is in the database, I will build a web app using Angular JS, That program will check the data and search for possible stock splits and inconsistent data.
Once the data is corrected, I will analyse it. Since Python has very powerful AI packages, I will use
Python to extend the web app above.
I will start by describing the data and some relevant topics for stock markets.