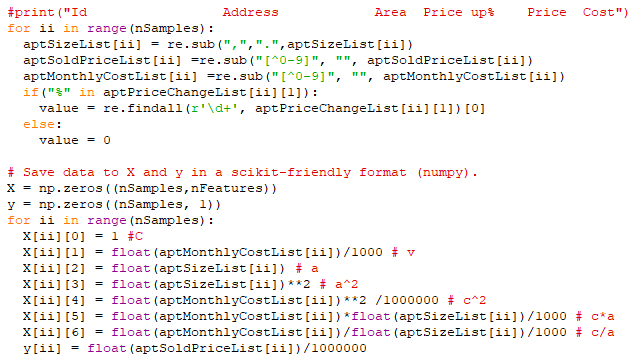
I've spent some time on reading and summarizing a couple of papers that are discussing how AI is impacting our thinking. After that, I've also had an AI agent summarizing the papers and discussing my conclusions.
Your Brain on ChatGPT
This paper from MIT compared three small groups of students that were to write essays with different levels of assistance: No assistance at all, Search Engines and Large Language Models.
The term self-efficacy reflects the student's confidence in his/her own ability to learn. The report mentioned that students low in self-efficacy may use LLM's to a larger extents than self-confident students. Cognitive Load versus Engagement
There is a difference between high-competence use of LLM and low-competence use. Higher competence uses LLM strategically for active learning, revisiting and synthesizing information to create coherent knowledge structures. This reduced cognitive strain while remaining engaged with material.
LLM bots as Instructor Bot and Emotional Support Bot can improve performance and reduce stress
Con's from LLM's: Laziness, one single answer compared with web searches, no person-person discussions, more superficial and effort-less learning.
The Illusion of Thinking
Large Reasoning Models are LLM's that can perform some kind of "reasoning" in different steps. Apple has investigated some models for simple puzzles. Depending on the task complexity, either LLM's are better (simple tasks), LRM are better (moderate complex tasks) and both collapse (complex tasks).
Put differently, will future employers allow employees to spend several hours reading and understanding complex topics by actually reading about it, or will employees be expected to use LLM's to quickly generate convincing TL;DR results that are more or less factual. The latter option may make employees lazy, worse in problem solving and independent thinking.